scrapy项目介绍
- General
- 项目基本使用
- scrapy整体介绍
- 3.1. scrapy组件
- 3.2. scrapy组件总结
- scrapy启动
- 4.1. Crawler-命令执行入口
- 4.2. Crawler.crawl 分析
- 4.3. ExecutionEngine.open_spider分析
- 总结
1. General
scrapy是底层采用twsited基于事件驱动模型的通讯框架来实现,包含Engine,Scheduler,Spider,Downloader,Pipline五大部分组成
2. 项目基本使用
1
2
3
4
| api: https://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/tutorial.html
scrapy startproject doubanmovie
cd doubanmovie
scrapy genspider movie duoban.com
|
3. scrapy整体介绍
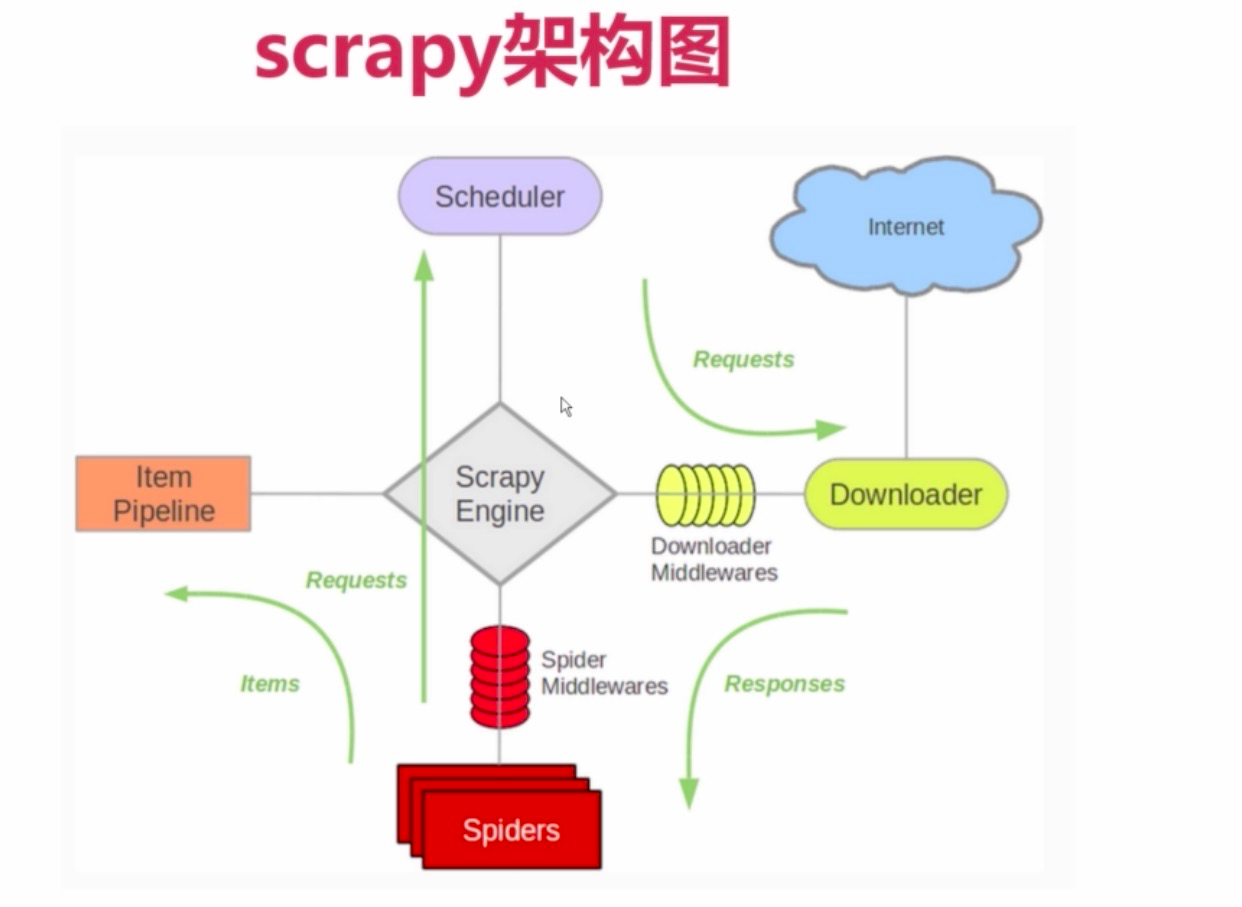
3.1. scrapy组件
- Spiders -> 用户自己编写的爬虫脚本,可自定义抓取意图
- pipline -> 负责输出结构化数据,可自定义输出位置
- Scheduler -> 负责管理任务、过滤任务、输出任务的调度器,存储、去重任务都在此控制
- Downloader -> 下载器,负责在网络上下载网页数据,输入待下载URL,输出下载结果
- Scrapy Engine -> 核心引擎,负责控制和调度各个组件,保证数据流转
- Downloader middlewares -> 介于引擎和下载器之间,可以在网页在下载前、后进行逻辑处理
- Spider middlewares -> 介于引擎和爬虫之间,可以在调用爬虫输入下载结果和输出请求/数据时进行逻辑
3.2. scrapy组件总结
- scrapy Engine启动调度Scheduler获取url种子
- Engine将种子传递给download下载返回response
- Engine将response传递给spider解析
- Engine将解析回来的scrapy Item传递给pipline
其中在2中种子传递用Downloader middlewares进一步封装。
4. scrapy启动
4.1. Crawler-命令执行入口
- 位于./python3.6/site-packages/scrapy/commands/crawl.py 中Command(ScrapyCommand) 是对scrapy命令解析执行. 调用逻辑run->self.crawler_process.crawl(spname, **opts.spargs)->self.crawler_process.start()。我们来看下crawler_process,该对象是在./python3.6/site-packages/scrapy/cmdline.py 中144行创建cmd.crawler_process = CrawlerProcess(settings)
- 接着看CrawlerProcess, 这理解之前先看下CrawlerProcess CrawlerRunner Crawler 三者的关系;首先从这里 class CrawlerProcess(CrawlerRunner) 看出CrawlerProcess继承CrawlerRunner,CrawlerRunner中的_create_crawler可以创建Crawler对象。而Crawler对象是加载全局配置文件Setting.py和爬虫文件的。 总结:./python3.6/site-packages/scrapy/commands/crawl.py 是解析scrapy命令的,第一步self.crawler_process.crawl(spname, **opts.spargs) 返回延迟对象,等待reactor轮询。第二部self.crawler_process.start() 启动轮询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| # CrawlerProcess函数说明
class CrawlerProcess(CrawlerRunner):
# 操作系统信号量回调函数注册(也就是ctrl+c 后调用的函数)
def __init__(self, settings=None, install_root_handler=True):...
# 信号量回调函数,ctrl+c结束当前进程,优雅的退出进程
def _signal_shutdown(self, signum, _):...
# 如果一次ctrl+c没有退出,则会触发当前操作,强制退出
def _signal_kill(self, signum, _):...
# 进程启动(thradpool配置,操作系统事件注册)
def start(self, stop_after_crawl=True):...
# 优雅退出,将退出添加到callback调用链条
def _graceful_stop_reactor(self):...
# 强制退出,直接退出reactor.stop()
def _stop_reactor(self, _=None):...
|
4.2. Crawler.crawl 分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| @defer.inlineCallbacks
def crawl(self, *args, **kwargs):
assert not self.crawling, "Crawling already taking place"
self.crawling = True
try:
# 加载自己写的Spieder
self.spider = self._create_spider(*args, **kwargs)
# 加载 ExecutionEngine 引擎
self.engine = self._create_engine()
# 自己写的start_requests会被执行,没有就走父类默认的start_requests
# 位于./python3.6/site-packages/scrapy/spiders/__init__.py
start_requests = iter(self.spider.start_requests())
# 启动引擎
yield self.engine.open_spider(self.spider, start_requests)
# 启动接受控制台命令
yield defer.maybeDeferred(self.engine.start)
except Exception:
self.crawling = False
if self.engine is not None:
yield self.engine.close()
raise
|
4.3. ExecutionEngine.open_spider分析
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| @defer.inlineCallbacks
def open_spider(self, spider, start_requests=(), close_if_idle=True):
assert self.has_capacity(), "No free spider slot when opening %r" % \
spider.name
logger.info("Spider opened", extra={'spider': spider})
# 调度要在下一个reactor循环中调用的函数,但前提是该函数自上次运行以来尚未被调度
nextcall = CallLaterOnce(self._next_request, spider)
# 调度器加载
scheduler = self.scheduler_cls.from_crawler(self.crawler)
# 中间件处理MiddleWare
start_requests = yield self.scraper.spidermw.process_start_requests(start_requests, spider)
# engine核心
slot = Slot(start_requests, close_if_idle, nextcall, scheduler)
self.slot = slot
self.spider = spider
# 打开调度器
yield scheduler.open(spider)
yield self.scraper.open_spider(spider)
self.crawler.stats.open_spider(spider)
# 发送信号,spider可以启动了
yield self.signals.send_catch_log_deferred(signals.spider_opened, spider=spider)
# reactor调度开始
slot.nextcall.schedule()
# 官网解释:Start running function every interval seconds. 也即是nextcall.schedule
slot.heartbeat.start(5)
|
5. 总结
看完以上代码流程,心中肯定会有如下一些疑问?
- @defer.inlineCallbacks 的作用是什么?reactor又是如何异步轮询?
- self.scraper.spidermw.process_start_requests 中间件是如何加载起作用的?
- yield self.signals.send_catch_log_deferred 的运作原理是什么,究竟是如何启动爬虫的?
- scheduler 调度器倒是如何被调度的?
- scrapy middelware 又是如何起作用的?